Welcome to LZN's Blog!
Wind extinguishes a candle but energizes fire.-
【COAP】大气科学类文献语料库建立
背单词找方法刷知乎的时候接触到了corpus(语料库)的概念,昨晚睡不着随便刷知乎,看到了这篇回答,也是利用语料库统计词频的方法,筛选出《经济学人》中专业词汇,从而有针对性地进行记忆,高效快速地训练自己能够读懂相关文章的能力。而作者没有局限于此,又对统计出的词频做了数据挖掘和数据分析,比如近几年经济学人对中国关注度的变化,对中国哪家互联网企业关注最多等等。看到这些,突然眼前一亮,为什么我们不能建立一个专业期刊的语料库,然后进行数据挖掘和分析呢?这下更睡不着了,决定取名为COAP (Corpus of Atmospheric Papers)。简单构思实现方法,认为这是可行的:
- 首先我们需要将指定期刊所有文章(带摘要的引文信息也可以,与paperhub联系),爬下来。
- 写词频统计程序和分析程序,对语料库进行整理分析。
可能遇到的困难:
-
期刊方自我保护:谁都不希望有人把自己所有的家当爬走,很可能会对下载进行限制。比如频率(这个可以通过延时解决)、数量(如果限制IP,没办法,只能换)、地址加密(这个也比较麻烦,所以需要学习爬虫)等等。今天简单看了JC的情况,发现地址虽然进行了加密,但是用爬虫应该还是能解决问题。
-
语义分析、正则表达式一直是弱项,这点需要额外加强,另外目前对语料库总数据量还不能确定(10-1000GB)区间吧,真正分析起来时间成本也是个问题,多线程需要考虑。
上述可能遇到的问题并非不能解决,简单设想,最好的工具就是python了,正好以此项目作为契机,入门python。一些资料留在这里,希望今年能把这个事情做出来!
-
【已解决】EXCEL+Shell抓取扇贝COCA TOP 20000
COCA 20000高频词汇。 COCA=Corpus of Contemporary American English (COCA) 这是英语国家使用频率最高的词汇集合。 从众多语料库(corpus)中提取。用大数据的方法从各种文体中自动生成一个词频表。这是当今最准确的词频表:美国当代语料库 coca 中的前20000个单词。 简单的说,coca就是把1990-2012年美国最有代表性的报纸,杂志,小说,学术,口语(口语可能是用的电视剧或者脱口秀之类的节目转录的)汇集起来,每部分各占1/5,生成4.5亿单词量语料库。 背完这个,应当就可以愉快的阅读纽约时报了。 希望你能成功。
上面是扇贝单词中COCA20000单词书的介绍。
不知道大家看完是不是之前就有这个想法:为什么我们背单词,不能集中下能搜集到的语言材料,然后将词汇出现的频次排个序呢?按照出现频次背上top一两万,日常能碰到的词汇不就都涵盖了么。确实是这样。
上个月在知乎一英语学习贴子上接触到了corpus(语料库)的概念,的确有人在用大数据自然语言分析的方法做这个事情。网上能搜到的有BNC和COCA,BNC公布了前15000,但是语料内容过于老旧,据说是80年代的,而COCA则是美国的,统计数据从90年代初到2012年,绝对的精华,非常优秀非常珍贵,但是只公开了前5000的高频词,20K的要接近40刀价格出售,没办法……
这几天托福4K已经差不多背完了,正在想着怎么把BNC15000导入,又查了一下扇贝单词书,大吃一惊,原来几天前(5月20日)已经有人把COCA top20000做成了单词书,而且售价199贝壳,相比于40USD,这可真是普度众生功德无量啊,果断收藏之!BNC15000也不用搞了,真爽。
正洋洋得意之时,突觉哪里不对,毕竟有个版权问题,万一哪天COCA找到扇贝,说你丫侵权,删掉删掉,一则词库没了要搁置一段时间,二则购买的话,又是接近三百块钱,这不完蛋了。虽然只是个概率问题,但毕竟还是存在风险的,计算下成本收益,与其承担这个不确定性,不妨写个脚本把单词全抓下来,万一删了还是有留底的,对冲风险,万无一失。下面来展示EXCEL+Linux的完美解决方案,当然,重点是分析问题的思路:
1. 地址分析
对于如此批量数据的处理,最基础的,我们要先搞清楚两个问题:
(1)查看数据是否有权限要求?
(2)数据组织结构是怎样的,源地址是否有规律?
对于第一个问题,如果不需要登录权限就可以查看单词书以及单词书下所有词汇,对我们来说无疑是非常有利的,因为不需要认证,很可能使用shell下的wget命令或者php get_file_contents就可以实现下载;
第二个问题,如果地址有规律,前面两个命令或函数配合循环直接搞定,问题将被大大简化,如果没有规律的话,就需要想办法进行遍历了。
首先在团队服务器用wget测试一下wordlist0-100这个页面能不能抓到,bingo!没问题,第一个问题直接解决。

对于第二个问题,我们分析一下地址:
http://www.shanbay.com/wordlist/103867/194194/
这是list0-100第一页的地址,可以末尾目录地址分为两个部分,10387是单词书编号,这个退回到单词书首页就可以发现,194194应该是单元编号,我们再跳到第二页,地址变成了这个:
http://www.shanbay.com/wordlist/103867/194194/?page=2
没错,只需要挂一个get参数就可以决定页数。而且扫了下每个单元,都是5页。Bingo,接下来的问题是,单元号是否有规律呢?
我们依次往下切几个单元看看:
http://www.shanbay.com/wordlist/103867/194194/ 0-100 http://www.shanbay.com/wordlist/103867/194197/ 100-200 http://www.shanbay.com/wordlist/103867/194200/ 200-300 http://www.shanbay.com/wordlist/103867/194203/ 300-400 http://www.shanbay.com/wordlist/103867/194230/ 1100-1200 http://www.shanbay.com/wordlist/103867/194863/ 20100-20200
从前几个单元来看,似乎单元号依次+3,这样很容易找到规律,按照这一规律推算,最后一个单元应该是194194+3*(20100/100)=194797,纳尼!实际却是194863,中间那几十个单元号哪里去了!!
估计这可能与单词书创建时单元提交错误,作者又重新提交有关,数据库没有删除错误的单元号。这么说,单元号可能是间断无规律的,换个思路,我们只能枚举了。
2. 枚举地址
首先查看源代码,发现词汇书首页单元链接部分共享统一的代码结构:
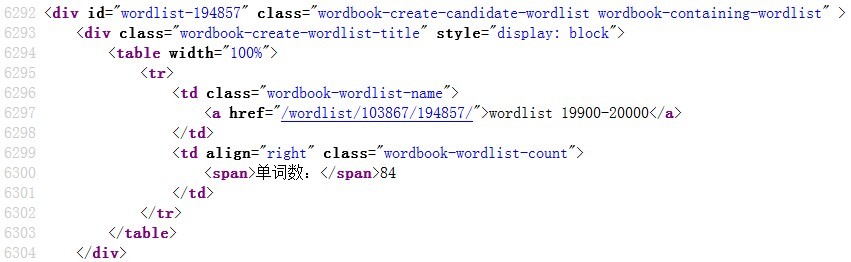
二话不说,全选复制,放到EXCEL中,A列:
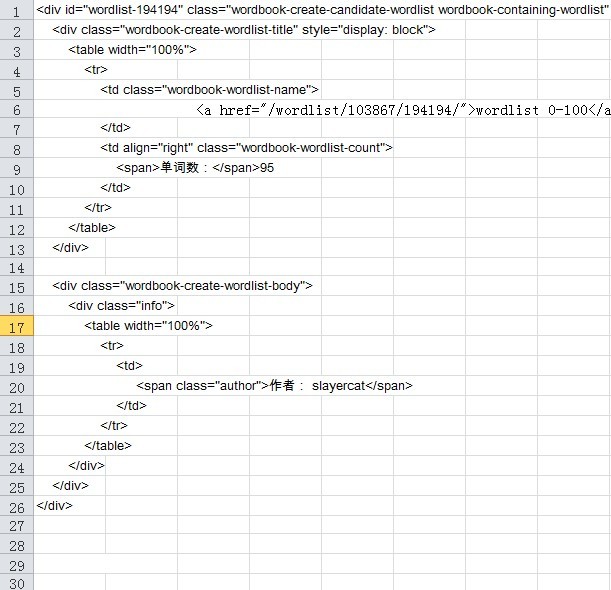
重点来了:由于每个单元结构都是固定格式,所以这些单元所占行数是固定的,因此我们所关注的链接地址出现的位置也是固定的:6行、36行、66行依次类推,所以,我们采用函数把这些行抽出来放到一个列中,随意百度,你就知道:
=INDEX(A:A,(ROW()-1)*30+6) 结果: <a href="/wordlist/103867/194194/">wordlist 0-100</a>
接下来则是喜闻乐见的拖啊托,然后分列,抽出链接部分,索性直接把命令补全:
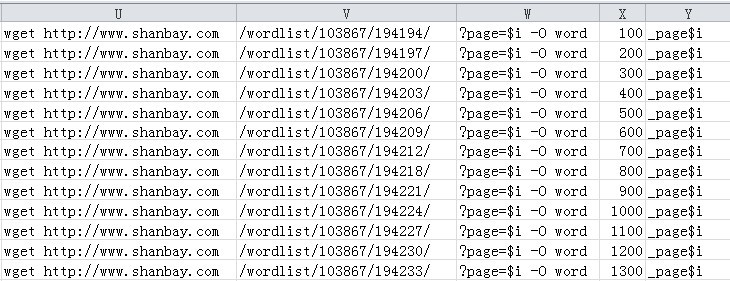
3. 脚本下载
接下来就水到渠成啦!复制粘贴,查找更换下多余tab空格,套个循环,sh执行!全部list down下来大概只用了5分钟左右,ls之:
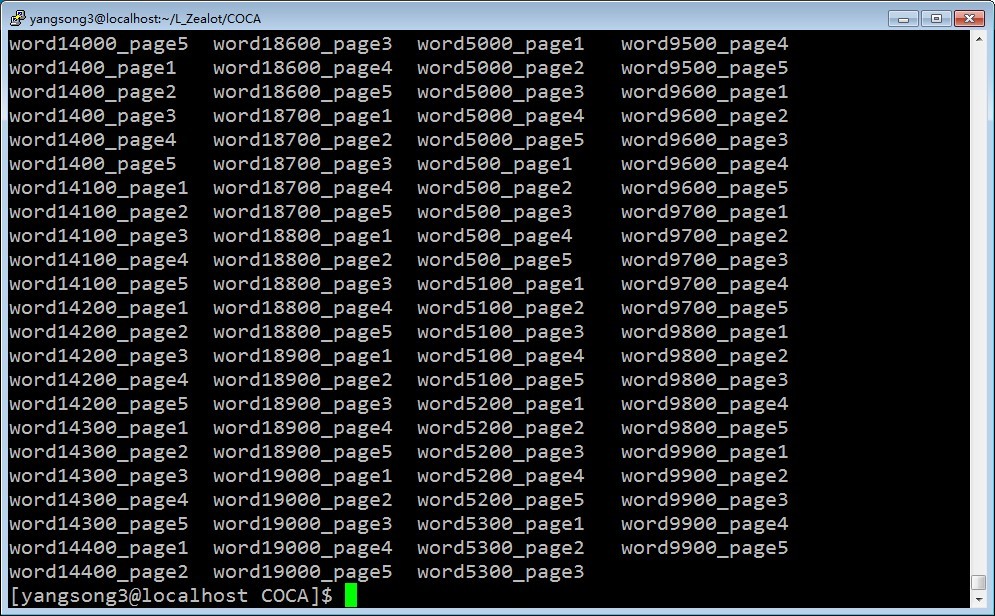
满满的成就感,且慢~grep一下html的关键label,再数个个数,看下是否都下载到了:

BINGO!不过单词书里16000+单词,为什么grep出18000+关键标签……查了个文件貌似除了汉语意思部分木有这个class了呀,不懂……回来满满找吧
ps: 5分钟能把这些单词upload到我脑子中不?LOL
-
【已解决】用winRAR+计划任务定期备份文件夹
三月份做好了linux下的全备份互联系统,Blackleach上工作用文件夹本想备份到Linux下,奈何没有做要数据和规则的分离,体积过大(40+G),winscp/NSF等可能也很费时不方便,用WinDirStat做了大文件分离后,还剩10+G,所以参考了这个帖子:
http://jingyan.baidu.com/article/3052f5a1ddb11097f31f8688.html
直接用winRAR+计划任务备份到另一块database硬盘上,我们文件过大,不需要存留旧版本,所以生成文件不挂时间戳,文中有几点需要设置的地方没有说清楚:
- 需要选定【备份】选项卡下“压缩前清除目标磁盘内容”的选项,否则第二次压缩时,由于同名文件存在,C盘无论多大都会被压缩过程中的临时文件占满。(估计可能是一个bug)
- 需要选定立刻执行,否则计划任务到时会弹出对话框,而不是立刻执行备份压缩。
- 压缩程度直接选存储级别,否则查看就会特别慢。
- 【e/acc】AI奇点 | 物理学家、e/acc运动创始人Guillaume Verdon与Lex Fridman播客实录 | 中英文完整版精译 IV(完结篇)
- 【e/acc】外星智能、卡尔达肖夫天梯、技术资本机器 | 物理学家、e/acc运动创始人Guillaume Verdon与Lex Fridman播客实录 | 中英文完整版精译 Part3
- 【e/acc】有效加速主义、量子热力学与AI未来 | 物理学家、e/acc运动创始人Guillaume Verdon与Lex Fridman播客实录 | 中英文完整版精译 II
- 【e/acc】有效加速主义、量子热力学与AI未来 | 物理学家、e/acc运动创始人Guillaume Verdon与Lex Fridman播客实录 | 中英文完整版精译 I
- 【酒后真言】AI工厂、物理智能:英伟达CEO黄仁勋与思科CEO Chuck Robbins炉边对话 | 中英文完整版精译
- 超级智能、顺从型AI、超人类主义、基督与超越:PayPal、Palantir联合创始人彼得·蒂尔2025年6月播客实录 | 中英文完整版精译(下篇)
- 技术停滞、回到未来、风险承担 | PayPal、Palantir联合创始人彼得·蒂尔2025年6月播客实录 | 中英文完整版精译 (上篇)
- 与外星人进行贸易,应该用什么货币?
- 2026年投资展望:Year of D——持盈保泰,因利制权
- R星创始人、《侠盗猎车手》与《荒野大镖客》创作者丹·豪瑟2025年11月播客实录 | 中英文完整版精译 Part3