COCA 20000高频词汇。 COCA=Corpus of Contemporary American English (COCA) 这是英语国家使用频率最高的词汇集合。 从众多语料库(corpus)中提取。用大数据的方法从各种文体中自动生成一个词频表。这是当今最准确的词频表:美国当代语料库 coca 中的前20000个单词。 简单的说,coca就是把1990-2012年美国最有代表性的报纸,杂志,小说,学术,口语(口语可能是用的电视剧或者脱口秀之类的节目转录的)汇集起来,每部分各占1/5,生成4.5亿单词量语料库。 背完这个,应当就可以愉快的阅读纽约时报了。 希望你能成功。
上面是扇贝单词中COCA20000单词书的介绍。
不知道大家看完是不是之前就有这个想法:为什么我们背单词,不能集中下能搜集到的语言材料,然后将词汇出现的频次排个序呢?按照出现频次背上top一两万,日常能碰到的词汇不就都涵盖了么。确实是这样。
上个月在知乎一英语学习贴子上接触到了corpus(语料库)的概念,的确有人在用大数据自然语言分析的方法做这个事情。网上能搜到的有BNC和COCA,BNC公布了前15000,但是语料内容过于老旧,据说是80年代的,而COCA则是美国的,统计数据从90年代初到2012年,绝对的精华,非常优秀非常珍贵,但是只公开了前5000的高频词,20K的要接近40刀价格出售,没办法……
这几天托福4K已经差不多背完了,正在想着怎么把BNC15000导入,又查了一下扇贝单词书,大吃一惊,原来几天前(5月20日)已经有人把COCA top20000做成了单词书,而且售价199贝壳,相比于40USD,这可真是普度众生功德无量啊,果断收藏之!BNC15000也不用搞了,真爽。
正洋洋得意之时,突觉哪里不对,毕竟有个版权问题,万一哪天COCA找到扇贝,说你丫侵权,删掉删掉,一则词库没了要搁置一段时间,二则购买的话,又是接近三百块钱,这不完蛋了。虽然只是个概率问题,但毕竟还是存在风险的,计算下成本收益,与其承担这个不确定性,不妨写个脚本把单词全抓下来,万一删了还是有留底的,对冲风险,万无一失。下面来展示EXCEL+Linux的完美解决方案,当然,重点是分析问题的思路:
1. 地址分析
对于如此批量数据的处理,最基础的,我们要先搞清楚两个问题:
(1)查看数据是否有权限要求?
(2)数据组织结构是怎样的,源地址是否有规律?
对于第一个问题,如果不需要登录权限就可以查看单词书以及单词书下所有词汇,对我们来说无疑是非常有利的,因为不需要认证,很可能使用shell下的wget命令或者php get_file_contents就可以实现下载;
第二个问题,如果地址有规律,前面两个命令或函数配合循环直接搞定,问题将被大大简化,如果没有规律的话,就需要想办法进行遍历了。
首先在团队服务器用wget测试一下wordlist0-100这个页面能不能抓到,bingo!没问题,第一个问题直接解决。

对于第二个问题,我们分析一下地址:
http://www.shanbay.com/wordlist/103867/194194/
这是list0-100第一页的地址,可以末尾目录地址分为两个部分,10387是单词书编号,这个退回到单词书首页就可以发现,194194应该是单元编号,我们再跳到第二页,地址变成了这个:
http://www.shanbay.com/wordlist/103867/194194/?page=2
没错,只需要挂一个get参数就可以决定页数。而且扫了下每个单元,都是5页。Bingo,接下来的问题是,单元号是否有规律呢?
我们依次往下切几个单元看看:
http://www.shanbay.com/wordlist/103867/194194/ 0-100 http://www.shanbay.com/wordlist/103867/194197/ 100-200 http://www.shanbay.com/wordlist/103867/194200/ 200-300 http://www.shanbay.com/wordlist/103867/194203/ 300-400 http://www.shanbay.com/wordlist/103867/194230/ 1100-1200 http://www.shanbay.com/wordlist/103867/194863/ 20100-20200
从前几个单元来看,似乎单元号依次+3,这样很容易找到规律,按照这一规律推算,最后一个单元应该是194194+3*(20100/100)=194797,纳尼!实际却是194863,中间那几十个单元号哪里去了!!
估计这可能与单词书创建时单元提交错误,作者又重新提交有关,数据库没有删除错误的单元号。这么说,单元号可能是间断无规律的,换个思路,我们只能枚举了。
2. 枚举地址
首先查看源代码,发现词汇书首页单元链接部分共享统一的代码结构:
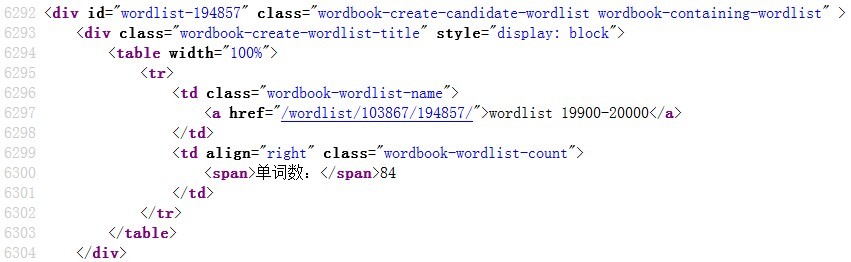
二话不说,全选复制,放到EXCEL中,A列:
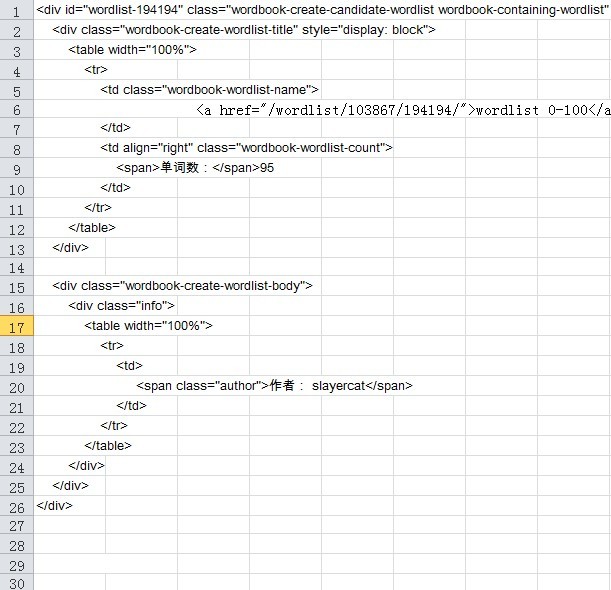
重点来了:由于每个单元结构都是固定格式,所以这些单元所占行数是固定的,因此我们所关注的链接地址出现的位置也是固定的:6行、36行、66行依次类推,所以,我们采用函数把这些行抽出来放到一个列中,随意百度,你就知道:
=INDEX(A:A,(ROW()-1)*30+6) 结果: <a href="/wordlist/103867/194194/">wordlist 0-100</a>
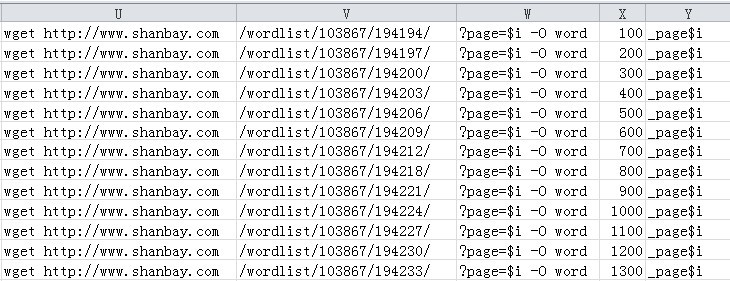
接下来则是喜闻乐见的拖啊托,然后分列,抽出链接部分,索性直接把命令补全:
3. 脚本下载
接下来就水到渠成啦!复制粘贴,查找更换下多余tab空格,套个循环,sh执行!全部list down下来大概只用了5分钟左右,ls之:
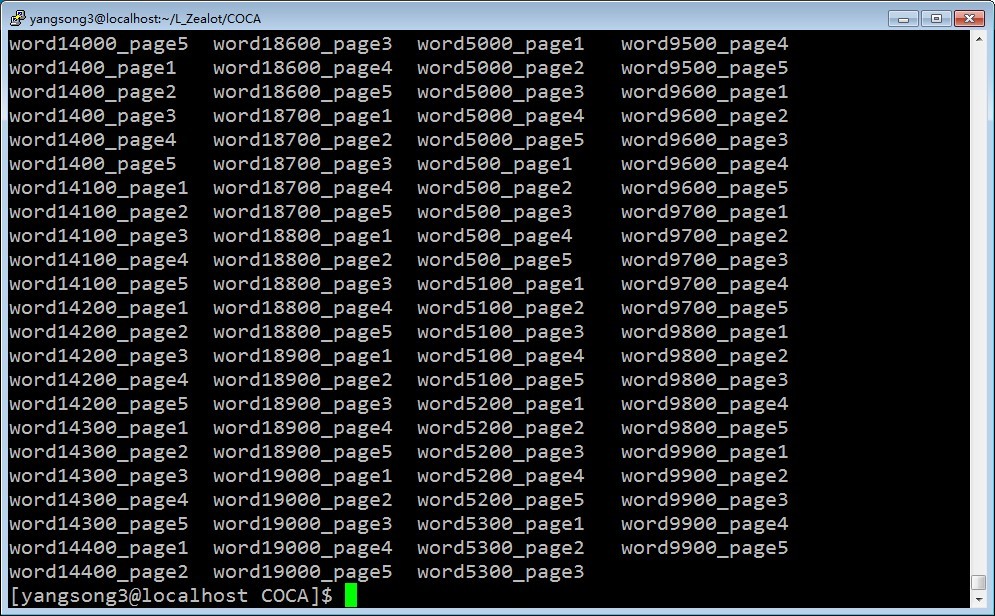
满满的成就感,且慢~grep一下html的关键label,再数个个数,看下是否都下载到了:

BINGO!不过单词书里16000+单词,为什么grep出18000+关键标签……查了个文件貌似除了汉语意思部分木有这个class了呀,不懂……回来满满找吧
ps: 5分钟能把这些单词upload到我脑子中不?LOL