Welcome to LZN's Blog!
Wind extinguishes a candle but energizes fire.-
【已解决】团队服务器搭建记录
1月底团队服务器到货,因假期没有进行搭建。这几天财务急需付款,遂与Jack_Cw一起进行搭建。操作系统:CentOS 6.5,安装过程略去不表。安装完成后配置网络着实折腾了一把,具体情况记录如下:
1.硬件及操作系统安装
- Linux安装步骤中配置IP及MAC地址,进入系统后完全不能上网,经检查IP地址过期。
- 更换IP地址及MAC,ping网关和DNS通畅,内网ssh通畅,外网(跨交换机)极其缓慢,网页打开极其困难。
- BIOS设置取消网卡IP自动分配,问题没有解决。
- 检查交换机,更换网线,设置路由,串联路由做交换,均不能解决。
- 拿笔记本做诊断,发现Linux系统都存在这一问题。
- 到Jack_Cw房间交换机诊断,同样存在问题。
- 尝试增加新的网络配置后,发现原有配置正常,但无法链接到新的网络配置。
- 采用给服务器增加一个新的无效的网络配置,原有配置即正常。问题解决。
结论:CentOS Linux系统bug,6.4/6.5/7.0均存在,不采用DHCP手动指定IP和MAC的情况下,必须再设置一个额外的网络配置(可以无效)原配置方能够正常使用。 #Up to 20150314#
2.软件包安装
2.1 Intel2015 C/C++/Fortran编译器
团队服务器落成,进行软件包安装,尝试安装intel2015编译器。过程与2013版本基本类似,第二步Lcense选项选择
3. I want to evaluate my product or activate later
缺少32位库,采用yum安装。
# yum install libstdc++.i686 --setopt=protected_multilib=false
参数用于忽略版本兼容检查。(默认系统已经安装64位库)
C/C++和Fortran编译器安装非常快,一共不到5分钟,不知是新版本优化了至强核心的编译还是RAID的原因。
安装完成后,拷贝intel.lic文件到/opt/intel/licenses下。
2.2 HDF5 1.8.14
先要安装zlib
#yum install zlib-devel #yum install zlib-devel #./configure --prefix=/usr/hdf5-1814 --with-zlib=/usr/lib64 #make #make check #make install
2.3 NETCDF 4.3.3.1
安装C库
./configure --prefix=/usr/netcdf-4331 --enable-netcdf-4 LDFLAGS="-L/usr/hdf5-1814/lib -L/usr/lib64" CPPFLAGS="-I/usr/hdf5-1814/include -I/usr/include" CC=icc $./make $./make check #./make install
安装fortran库,注意fortran库对应的netcdf版本号为4.4.2,但是也需要安装到与C库相同的目录下。
$./configure --prefix=/usr/netcdf-4331 LDFLAGS="-L/usr/netcdf-4331/lib" CPPFLAGS="-I/usr/netcdf-4331/include" FC=ifort $./make $./make check #./make install
检查安装情况
$nf-config --all $nf-config --flibs
2.4开启www服务
chkconfig mysqld on chkconfig httpd on service httpd start service mysqld start
vi /etc/httpd/conf/httpd.conf
修改 User和Group行 User yangsong3 Group yangsong3
chown -R yangsong3:yangsong3 www/
#Up to 20150317#
-
【已解决】CESM绘制、修改模式地形高度
修改inputdata/cam/topo下USGS的地形数据。变量为PHIS(地表位势高度[m^2/s^2]),除以9.81[m/s^2]即可。
参见这里,这是一个古气候模拟的用户手册。
-
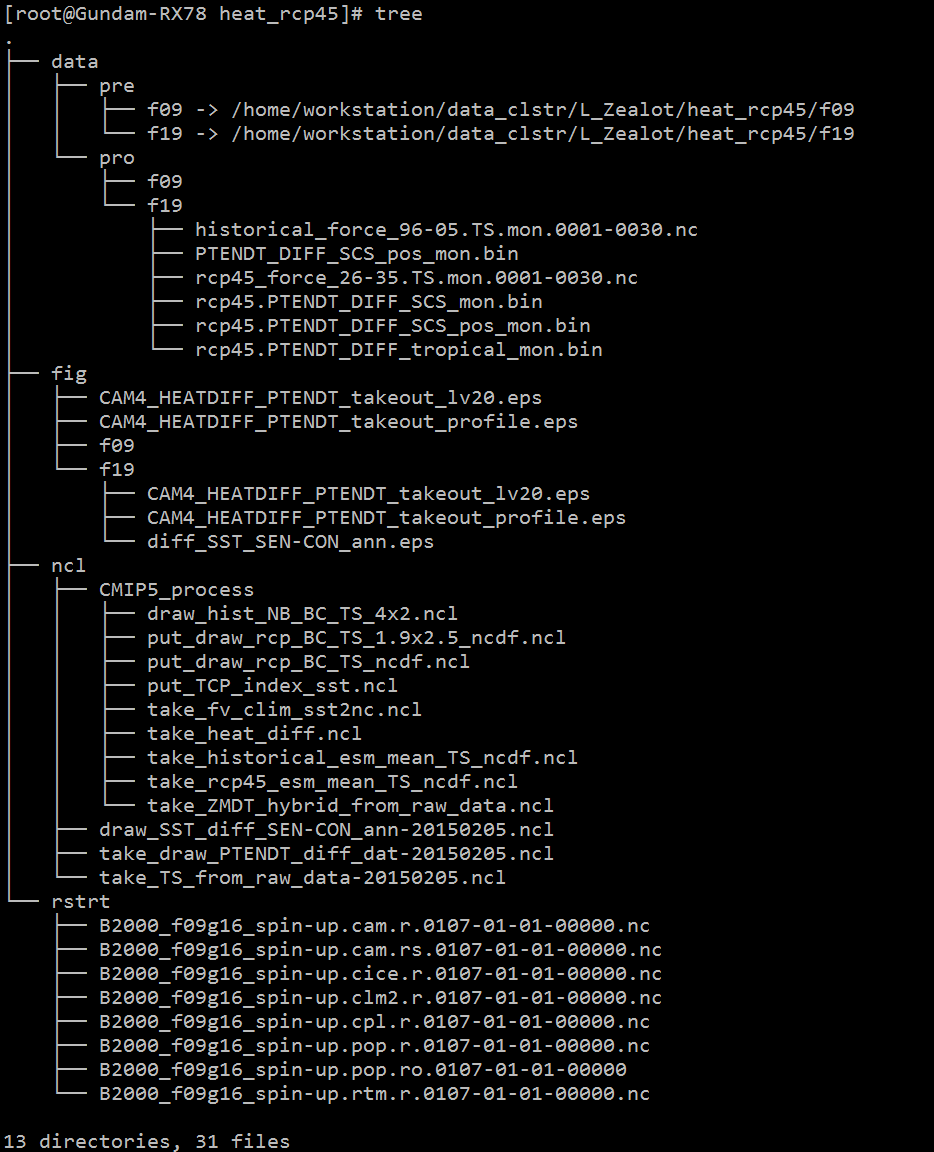
【已解决】Linux下查看目录树
希望查看某一项目的目录结构,有目录树的形式最好了。查了下,这个可以
find . -type d -print
但是效果并不美观

终极解决方案是root下装个tree命令
yum install tree
然后tree就可以了
效果:
如果只显示目录:
tree -d
Archives
Principle
Featured Articles
Tags
Recent Posts
- 【e/acc】AI奇点 | 物理学家、e/acc运动创始人Guillaume Verdon与Lex Fridman播客实录 | 中英文完整版精译 IV(完结篇)
- 【e/acc】外星智能、卡尔达肖夫天梯、技术资本机器 | 物理学家、e/acc运动创始人Guillaume Verdon与Lex Fridman播客实录 | 中英文完整版精译 Part3
- 【e/acc】有效加速主义、量子热力学与AI未来 | 物理学家、e/acc运动创始人Guillaume Verdon与Lex Fridman播客实录 | 中英文完整版精译 II
- 【e/acc】有效加速主义、量子热力学与AI未来 | 物理学家、e/acc运动创始人Guillaume Verdon与Lex Fridman播客实录 | 中英文完整版精译 I
- 【酒后真言】AI工厂、物理智能:英伟达CEO黄仁勋与思科CEO Chuck Robbins炉边对话 | 中英文完整版精译
- 超级智能、顺从型AI、超人类主义、基督与超越:PayPal、Palantir联合创始人彼得·蒂尔2025年6月播客实录 | 中英文完整版精译(下篇)
- 技术停滞、回到未来、风险承担 | PayPal、Palantir联合创始人彼得·蒂尔2025年6月播客实录 | 中英文完整版精译 (上篇)
- 与外星人进行贸易,应该用什么货币?
- 2026年投资展望:Year of D——持盈保泰,因利制权
- R星创始人、《侠盗猎车手》与《荒野大镖客》创作者丹·豪瑟2025年11月播客实录 | 中英文完整版精译 Part3
Categories