应老板项目要求,CAM的分辨率早晚要shift到F05的水平,前两天在学校四期平台上测试了下,默认配置,CAM4物理,96个核,900s积分时间,运行情况实在惨不忍睹:
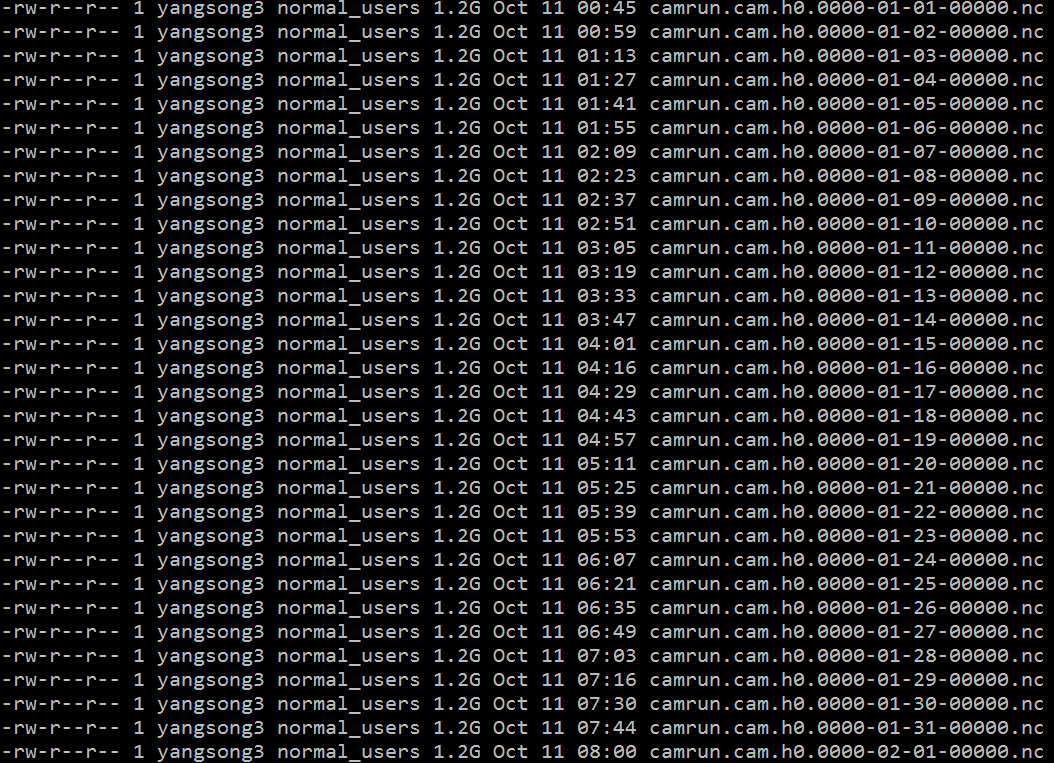
运行一个月用了整整一晚上,十几分钟才能输出一天,一个文件1.2G,我擦嘞。
转到天河二号,直接调用了1200个核心,物理包用的CAM5,大概三四分钟出来一天的样子,发现IO是个大瓶颈。测试改PE层,只有atm用1200个核心,其他用120个核心,依然是sequential执行,效果差不多。
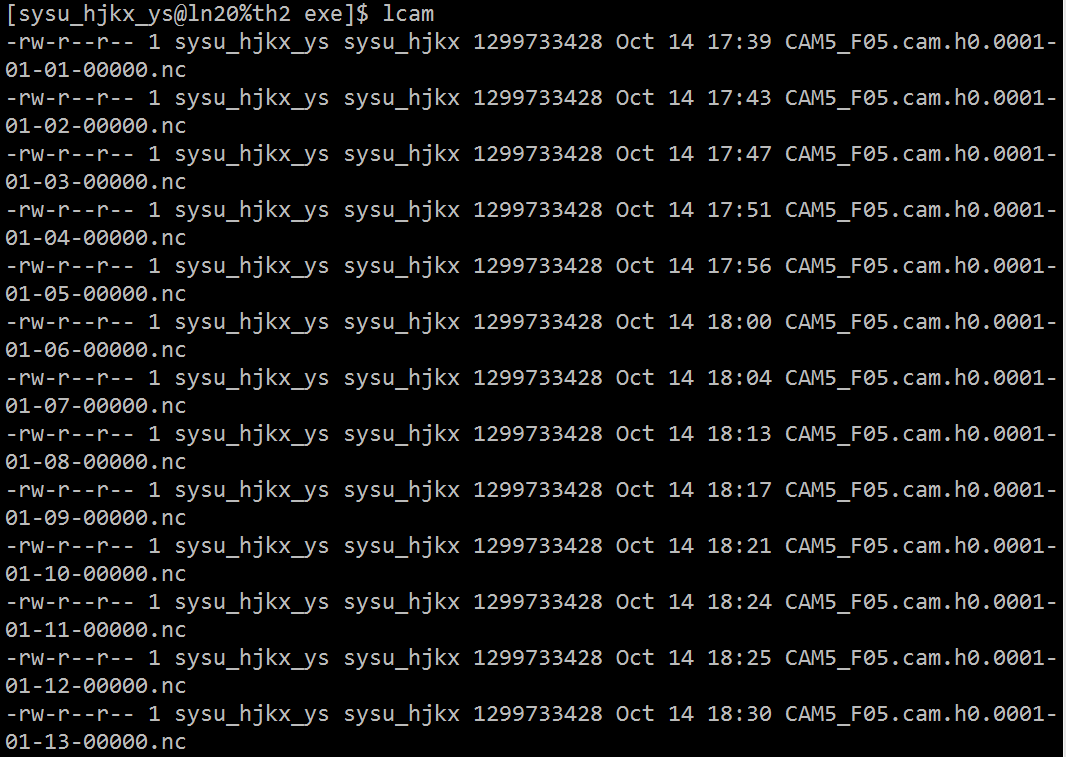
决定尝试采用concurrent的方式进行,UG上给的1800+个核心,而且用了多线程的方式,还是先不冒险多线程了吧,atm缩减到768,其他大概凑天河二号节点情况24核心的倍数,具体配置如下,几个concurrent的层次模块与UG上一致。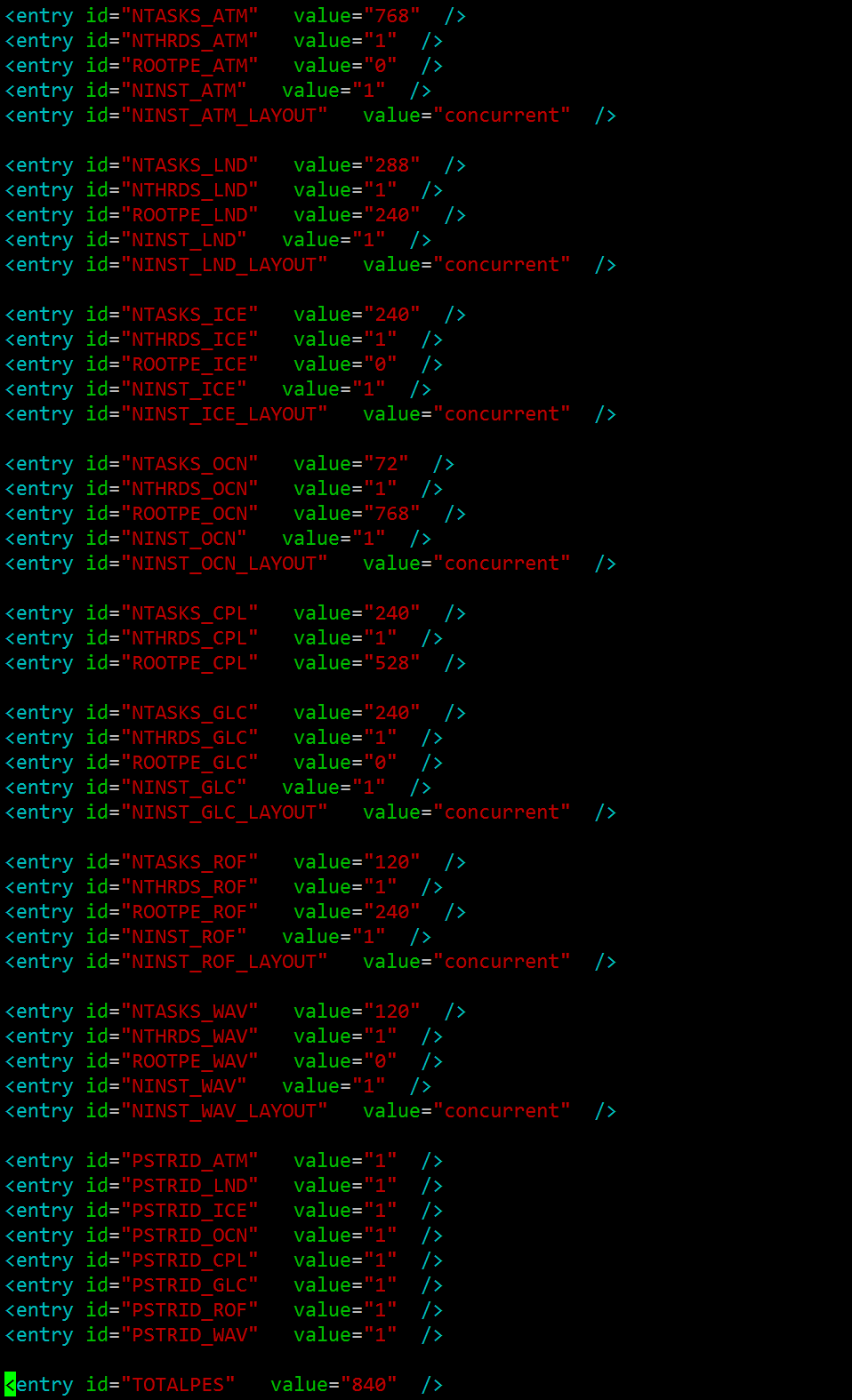
运行速度貌似差别不大,可以省核时了。但是IO实在是太慢了,1秒钟才能写入10-20M+?我擦嘞,这是网速来着……1分钟+才能写出一个日平均,真是丧心病狂啊……回来得问问超算中心,PIO究竟能不能实现。